Introduction#
Here we will talk about where Kokkos comes from, how to do simple things with parallel dispatch in Kokkos, and how to integrate it into a build system and make it work together with your applications.
What is Kokkos?#
Kokkos is a performance portability framework for C++. It allows you to write single-source implementations using a descriptive programming model in ISO standard C++, and allows you to compile your code for CPUs and GPUs.
It is something that has been around for a while. It was established in 2012 at the Sandia national laboratory. Since then, it has gotten a lot of buy-in from DOE national laboratory. There are now over 100 projects and 500 developers actively using Kokkos. There is dedicated development staff for Kokkos at different national labs which supports these projects.
Kokkos does not require you to have any knowledge of exotic software stacks. It works with standard mainline compilers (gcc, clang, nvcc, rocm…)
There are many good online resources for Kokkos. The main documentation site kokkos.org is the one-stop-shop. From there you can find the main github repository, the kokkos-tutorials repository, and the Slack channel. You can ask anything from very basic questions to very complicated semantic questions about what happens inside the library functions.
Why Kokkos? If we look at the HPC hardware landscape, the current generation of machines use mostly OpenMP 3 and CUDA programming models. On the CPU-based systems, OpenMP is the main programming model, while on GPU-enabled systems the primary model is CUDA. If we look at the upcoming (now current) generation, the programming models include OpenMP 5, CUDA, HIP, and SYCL (DPC++). If we do not use a performance portability framework, we need to re-implement workloads for each different programming model.
If we have all of these different programming models, why is that a problem? It is expensive and time-consuming to re-write code. Industry standard tells us that a full-time software engineer writes about 10 lines of production code per hour. Typical HPC production apps are 300k+ lines of code. Sandia alone maintains a few dozen such applications. There are extremely large projects like Trilinos with millions of lines of code. For such a project, a conservative estimate is that you would need to re-write 10% of the application. If we just do the math, switching programming models can cost multiple person-years per app!
The Kokkos solution:
- Kokkos is first and foremost a C++ programming model for performance portability. It is implemented as a template library on top of CUDA, HIP, OpenMP…
- It aims to be descriptive not prescriptive. It gives you the ability to express how your code works and what it does, and then Kokkos maps that to the underlying hardware resources.
- Trying to align with the developments in the C++ standard
- It is an expanding solution for common needs of modern science and engineering codes
- A common problem is a need for highly optimized linear algebra and mathematical libraries
- We need tools for debugging, profiling, and tuning
- Utilities for integration with Fortran and Python
- Kokkos is open source. All of the work happens in the open-source github repository
- There are hundreds of active users at many large institutions. At this point, there are many instances of users answering the questions of users, a sign of a healthy ecosystem.
The idea is that you write your libraries and applications using Kokkos, and then Kokkos does the work of mapping that onto all of the new hardware platforms as they become available. The goal here is that if you wrote your code so that it works on the current generation of HPC systems, then you will not need to change anything other than some build options when you want to run on newer generations of machines.
The Kokkos Ecosystem#
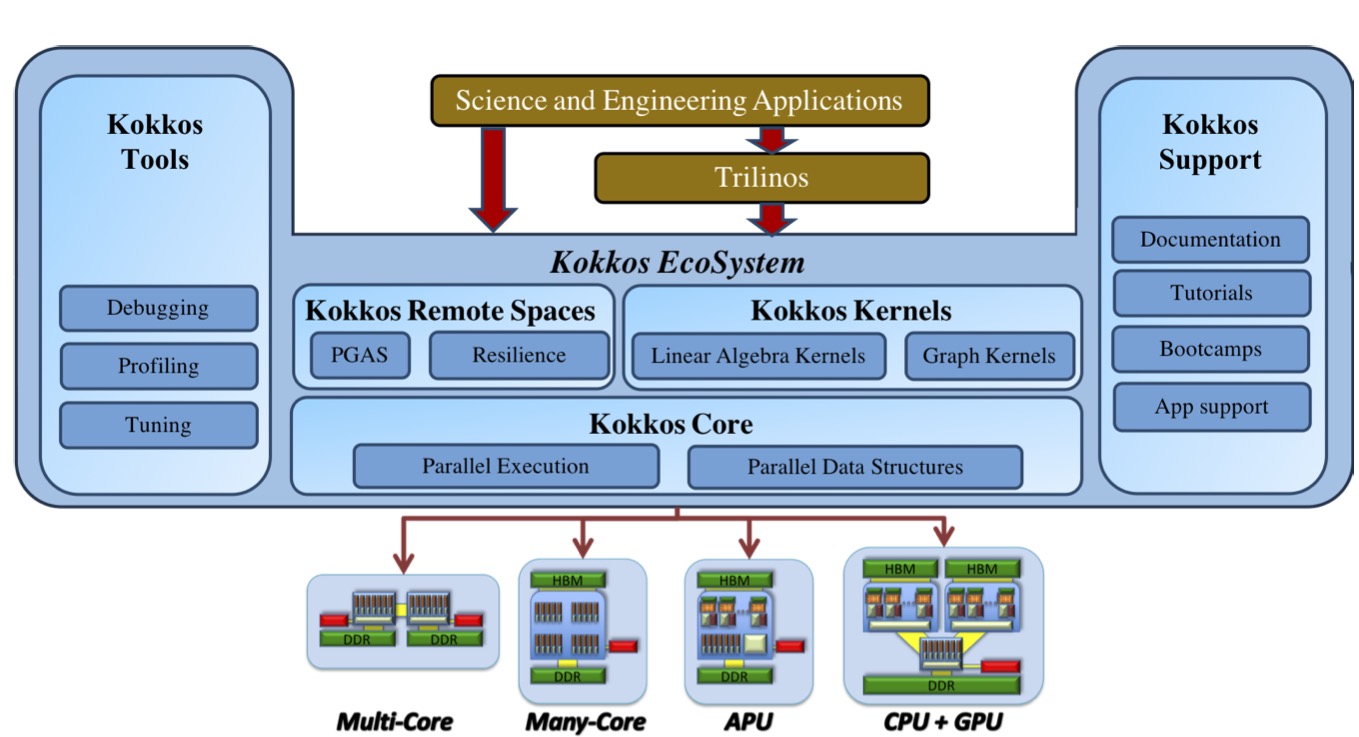
At the bottom is the kokkos programming model, which handles things like parallel execution and parallel data structures.
Built on top of that, we have other projects:
- Kokkos kernels contains some optimized linear algebra and graph kernels
- Kokkos remote spaces is an experimental project with support for more complicated distributed domains, as well as some functionality for resilience.
- Kokkos tools includes debugging, profiling, and tuning tools which integrate directly with Kokkos. The other pieces also have the same integrations built in so that you can get insight into these things.
- Kokkos support was originally funded by the exascale computing project, and is responsible for providing documentation, tutorials, and app support
Behind all of this is the Kokkos team, which spans five national labs in the US as well as the Swiss Computing Center.
Kokkos and the C++ Standard#
Kokkos is very much trying to align with the C++ standard. This is part of the long-term vision. To make it long-term maintainable and sustainable, we are trying to improve the ISO C++ standard. We find features in Kokkos that have broadly been useful in the real world, and we propose them as new features in the C++ standard. When such features are actually accepted, then the existing capabilities can be re-implemented in terms of the new C++ features. This gives you a smooth transition for capabilities that are currently provided by Kokkos, or provided in new features in the C++ standard. In particular that means that when the new compiler features become available, we can switch out in the Kokkos API to the new compiler features, and then you get the versions that have been optimized by the compiler vendors.
There are two examples of this to highlight here:
- In C++11 we had std::atomics, but they are insufficient for HPC. These are objects, not functions, and you can only access them atomically. You can not write one kernel in which you want to access a data structure atomically, but in the next function where you may have no write conflicts you can not just access the same structure non-atomically. We proposed something called atomic_ref which wraps standard allocations. It works for sizes which can’t be done lock-free (e.g.
complex<double>)).std:atomic_refis now a feature in C++20 - A big problem with C++ is that it does not provide multi dimensional arrays natively. For C++23 proposed
std::mdspanbased onKokkos::Viewlike arrays. Importantly it uses reference semantics. It has compile and runtime extents which you can mix. This means that you can efficiently express very small things (like 4x4 matrices) very efficiently. It has data layouts to allow for adapting hardware specific access patterns. And you can have subviews.
// Kokkos
View<int**[5], LayoutLeft> a("A", 10, 12); a(3, 5, 1) = 5;
// std::mdspan in ISO C++23
using ext = extents<dynamic_extent, dynamic_extent, 5>;
basic_mdspan<int, ext, layout_left> a(ptr, 10, 12); a(3, 5, 1) += 5;There is a very long timeline for these features. For example, std::mdspan took about 11 years between being implemented in Kokkos and making it into mainline compiler implementations.
Performance Portability#
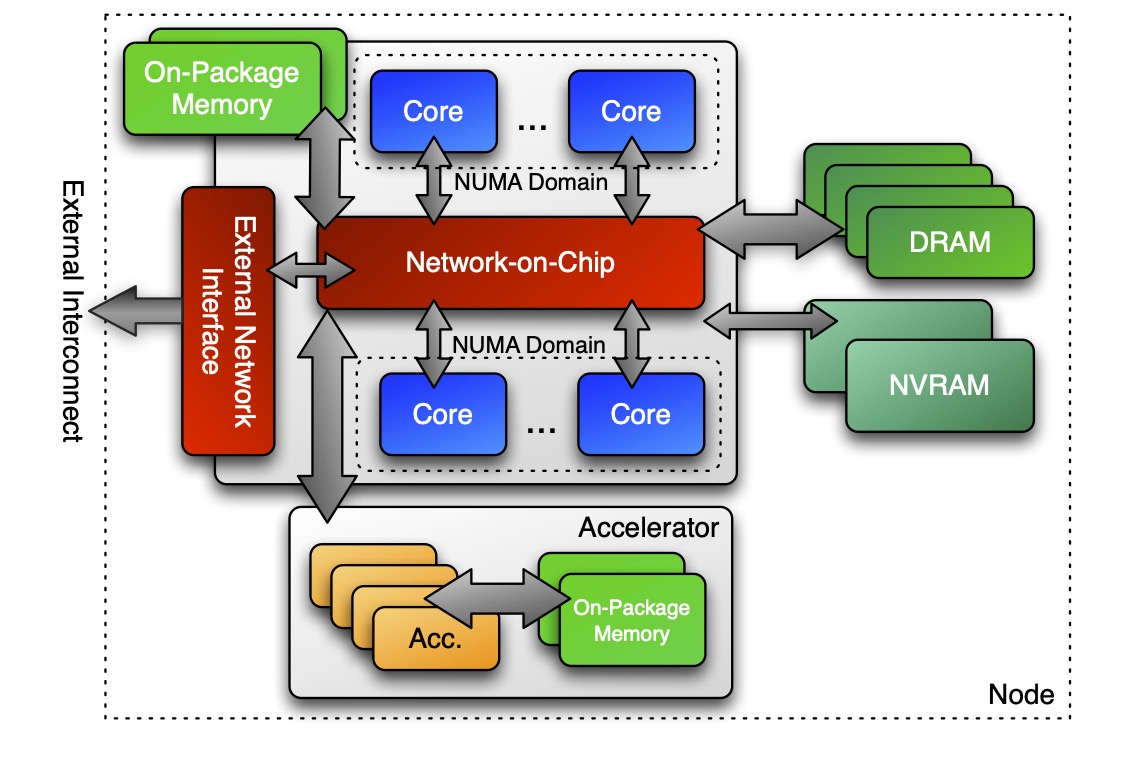
Generally, this is the kind of architecture we are aiming to support. You have a node with some CPU cores, with an attached accelerator (or multiple accelerators). You have some attached DRAM and/or NVRAM. Kokkos is designed to be able to express codes that need to use all of these parts.
There is a difference between portability and performance portability. For example, you can implement things like locks on modern GPUs. That will work, but it is not thread scalable. Things with work at one regime of parallelism like locks (fine for ~10 threads) scale very poorly up to 100,000 threads on the GPU.
Our goal is to write one implementation which
- compiles and runs on multiple architectures
- obtains performant memory access patterns across architectures
- can leverage architecture-specific features where possible, and do that in a transparent way
Concepts for Data Parallelism#
Suppose we have a code like this:
for (element = 0; element < numElements; ++element) {
total = 0;
for (qp = 0; qp < numQPs; ++qp) {
total += dot(left[element][qp], right[element][qp]);
}
elementValues[element] = total;
}
which should look very familiar for any finite element quadrature calculation veteran. We have a pattern defined by the for. There is an execution policy which implicitly guarantees that element 6 is executed after element 5 is. And then there is the body, which is the unit of work that is being done for every iteration.
The pattern and the policy drive the computational body.

If you want to parallelize the loop using threads, we could add the #pragma omp parallel to change the execution policy from “serial” to “parallel”. If you want to be pedantic, there is actually a lot more implied in this. That omp parallel for actually says to split the numElements range into different sections, give each section to a thread, and then run in a serial loop so that a thread is given a loop with a lower number before a loop with a higher number. This is simple to use, and works fairly well on multi-core CPUs.

But if you want to use that on GPUs, things get a bit more complicated. You can do this in OpenMP. You have to tell it that you want to offload it to a target. There are also data mapping clauses you have to add. Everything you want to access in the loop body needs to be mapped to data on the device. You also need to set a number of teams and threads and control how the loop is mapped to the underlying hardware, because the defaults are not generally the best.
In principle that works, but does it also give you performance? Performance usually depends strongly on the memory access pattern. Suppose we have a loop similar to what we had before:
#pragma something, openCL, etc.
for (element = 0; element < numElements; ++element) {
total = 0;
for (qp = 0; qp < numQPs; ++qp) {
total += left[element * numQPs * vectorSize + qp * vectorSize + i] *
right[element * numQPs * vectorSize + qp * vectorSize + i];
}
}In the innermost loop, there is a data access into two arrays. But these 1-D arrays represent is actually 3D data structure, and we have this canonical calculation for the indexing into the array. What happens here is that the indexing is hard-coded, and the body expresses the mapping of indices to memory. While this data layout implicit in this case is good for CPUs, the strided access pattern is very bad for GPUs and you lose an order of magnitude performance compared to what you would get with a different access pattern. The memory access pattern must depend on the architecture.
Data Parallel Patterns#
Let’s talk about how we express data parallel patterns in Kokkos and how we describe the work. Generally Kokkos maps work onto execution resources.
- Each call to your computational body is what we call one unit of work. In principle we reserve the right to schedule any unit of work individually.
- Each unit of work is identified by its iteration index
- The iteration range defines the total amount of work.
You give an iteration range and computational body, and Kokkos decides how to map that work onto execution resources.
The fundamental way to give computational bodies to Kokkos is functors. This is pretty standard in C++. If you use things like standard library algorithms, you similarly provide loop bodies as functors. A functor is just a function with data. You provide a struct with a () operator defined. What you put into that operator is your computational body.
When you provide work, you provide an iteration space and a functor. The primary way to do this is Kokkos::parallel_for. Kokkos assigns work items to functors one-by-one. Concurrency and ordering of parallel iterations is not guaranteed by the Kokkos runtime. We can hand out indices in any order as we see fit, according to the execution space we are working with. This property gives Kokkos the freedom to vectorize loops and map it to various architectures.
Now, how do we pass data to computational bodies? A parallel functor body must have access to all the data it needs through the functor’s data members:
struct AtomForceFunctor {
ForceType _atomForces;
AtomDataType _atomData;
AtomForceFunctor(/* args /*) {...}
void operator()(const int64_t atomIndex) const {
_atomForces[atomIndex] = calculateForce(_atomData);
}
};
If we wanted to reproduce serial execution with this functor, it would look like:
// Serial
for (atomIndex = 0; atomIndex < numberOfAtoms; ++atomIndex) {
atomForces[atomIndex] = calculateForce(data);
}
// Functor
AtomForceFunctor functor(atomForces, data);
for (atomIndex = 0; atomIndex < numberOfAtoms; ++atomIndex){
functor(atomIndex);
}This is actually pretty close to what the serial backend of Kokkos looks like. For the complete picture of executing a functor in a Kokkos::parallel_for, we would have:
struct AtomForceFunctor {
ForceType _atomForces;
AtomDataType _atomData;
AtomForceFunctor(ForceType atomForces, AtomDataType data) :
_atomForces(atomForces), _atomData(data) {}
void operator()(const int64_t atomIndex) const {
_atomForces[atomIndex] = calculateForce(_atomData);
}
}
AtomForceFunctor functor(atomForces, data);
Kokkos::parallel_for(numberOfAtoms, functor);This gets to be pretty tedious because it’s very mechanical. We just copy the loop body into the operator, and then we check every variable we use, make those member variables, and write a constructor that initializes all of them. C++ committee recognized this a long time ago, and since C++11 we have lambdas. This is just a nice syntax that auto-generates a functor for you:

The compiler looks at the body, identifies everything that you access, and the [=] syntax defines how those members are initialized. [=] means initialize all members by copy, [&] would mean capture by reference.
For portability to a GPU a lambda must capture by value [=]. That means every data member must be viable on the GPU. Don’t capture containers (e.g. std::vector) by value because it will copy the container’s entire contents. And of course you can’t have pointers to host variables in there.
Let’s consider an example of scalar integration with a Riemann-sum style numerical integration
\[y = \int _{lower} ^{upper} function(x) \dd x\]If we do this in a serial way, we might write
double totalIntegral = 0;
for (int64_t i = 0; i < numberOfIntervals; ++i) {
const double x = lower + (i/numberOfIntervals) * (upper - lower);
const double thisIntervalsContribution = function(x);
totalIntegral += thisIntervalsContribution;
}
totalIntegral *= dx;How do we parallelize it correctly? If we just make it a parallel_for, define the number of intervals, and give it the loop body, an incorrect attempt might look like this:
double totalIntegral = 0;
Kokkos::parallel_for(numberOfIntervals, [=] (const int64_t index) {
const double x = lower + (index/numberOfIntervals) * (upper - lower);
totalIntegral += function(x);
});
totalIntegral *= dx;But in this case the compiler will tell you that you cannot increment totalIntegral because lambdas are always const objects. We treat them const because modifications of data members are lost at the end of the loop, and also we reserve the right to give every thread a copy of the lambda to avoid shared memory contention issues. As a consequence, we cannot do that accumulation in the loop body as we might expect. We could just capture a pointer to totalIntegral, but this introduces a race condition because there is a load-increment-write cycle for each thread. If one thread loads the value just before another thread writes to it, then the first thread will overwrite the value and lose the contribution from the first thread.
We need to use the right pattern here. In this case, we want to use a reduction instead of a for. Reductions are patterns that combine the results contributed by parallel work:
double totalIntegral = 0;
parallel_reduce(numberOfIntervals, [=] (const int64_t i, double& valueToUpdate) {
valueToUpdate += function(...);
}, totalIntegral);Here the operator takes two arguments: a work index and a value to update. The second argument is a thread-private value that is managed by Kokkos. There is a final aggregation step at the end of the loop to combine the private results from each thread. This is exactly what OpenMP would be doing in a #pragma omp parallel for reduction(...).
Warning: Parallelism is not free. Dispatching parallel work has a non-negligible cost. This is generally expressed as Amdahl’s Law:
\[T = \alpha + \frac{\beta * N}{P}\]- \( \alpha \) = dispatch overhead
- \( \beta \) = time for a unit of work
- \( N \) = number of units of work
- \( P \) = available concurrency
The optimal speedup is then
\[\frac{P}{1 + \frac{\alpha * P}{\beta * N}}\]This means we need \( \alpha * P \gg \beta * N \). All runtimes strive to minimize the launch overhead \( \alpha \) as much as possible. We are essentially limited by whatever the programming model has defined. This latency is generally on the order of \( 5\mu s \). In principle you can do a lot of work in that amount of time. You could find more parallelism to increase \( N \) or merge (fuse) parallel operations to increase \( \beta \). But if you have a vector add of 100 elements, then that’s probably not the right place to parallelize that as a kernel launch to the GPU.
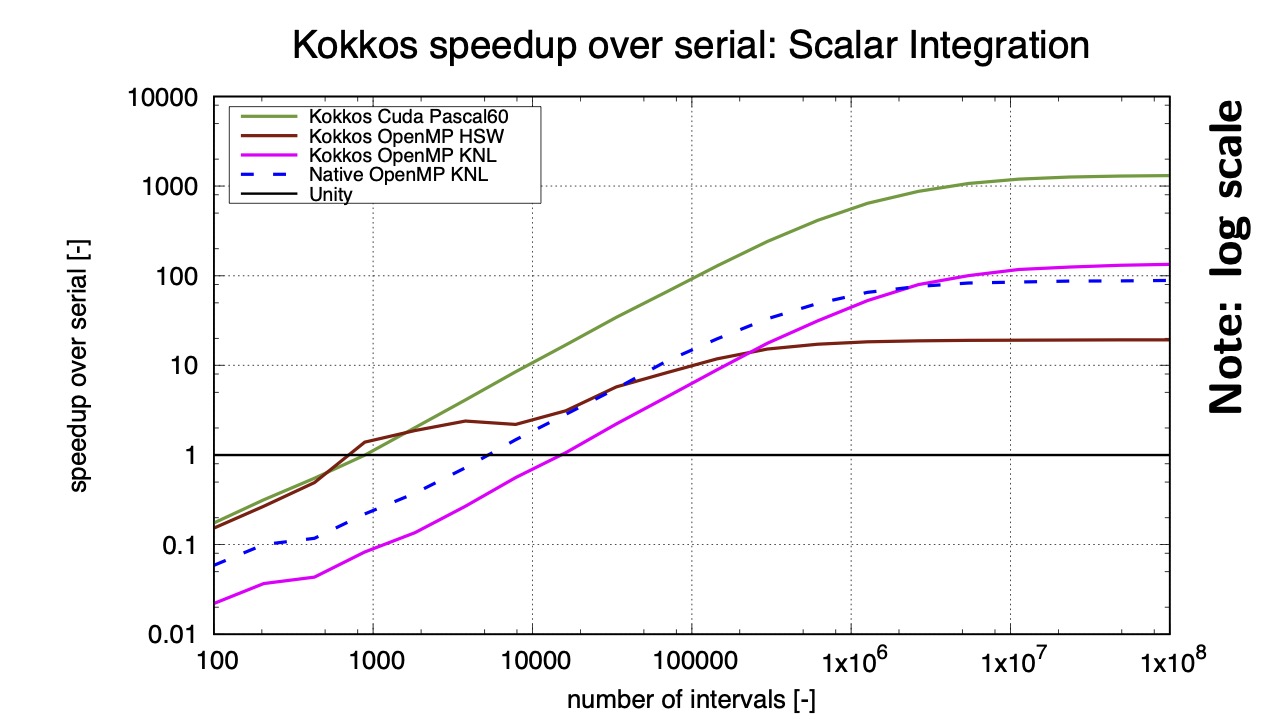
In this example with no data accesses, we see that you need on the order of 1,000-10,000 iterations to break even with serial execution on a single core.
Name your kernels! Kokkos allows you to give unique names to each kernel. This is immensely useful for debugging and profiling. You can provide an optional string argument to non-nested parallel patterns. The label doesn’t need to be unique, but it is helpful if it is. You can give it anything that is convertible to std::string. This is used by the profiling and debugging tools.
double totalIntegral = 0;
parallel_reduce("Reduction", numberOfIntervals,
[=] (const int64_t i, double& valueToUpdate) {
valueToUpdate += function(...);
}, totalIntegral);Building Kokkos#
There’s a good bit of content here about how to integrate Kokkos into a project. Realistically, there are two options: The best option is to install Kokkos via CMake, and then build your application against it (e.g. find_package(Kokkos REQUIRED)). There is also support for the Spack package manager, which is popular among DOE projects.
In the spirit of C++ for code performance portability, modern CMake aims for build system portability. Projects that depend on Kokkos should be agnostic to the exact build configuration of Kokkos. There are not CUDA details in your C++ project or your CMake configuration! These are all internal to Kokkos. A single build system call in your project should configure all of the relevant compiler and linker flags
add_library(myLib goTeamVenture.cpp)
target_link_libraries(myLib PUBLIC Kokkos::kokkos)Kokkos configuration options are enabled/disabled via CMake: cmake -DKokkos_XYZ=ON The most important options are the backend options. Numerous Kokkos backends can be activated, but only one GPU, one parallel CPU, and the Serial backend can be enabled at the same time.
-DKokkos_ENABLE_CUDA=ON-DKokkos_ENABLE_HIP=ON-DKokkos_ENABLE_OPENMP=ON-DKokkos_ENABLE_OPENMPTARGET=ON
You will get output when you configure Kokkos in the CMake output, telling you which execution spaces were enabled
-- Found Kokkos: /Users/evan/tools/kokkos/lib/cmake/Kokkos (version 5.0.1)
-- Kokkos OpenMP backend enabled
-- Kokkos Serial backend enabled
-- Kokkos version: 5.0.1
-- Kokkos devices: OPENMP;SERIALDevice backends need the correct architecture to be specified (CUDA, OpenMPTarget, HIP)
-DKokkos_ARCH_VOLTA70=ON-DKokkos_ARCH_VEGA906=ON
It is recommended that you also enable a host backend architecture to enable architecture-specific optimizations. Otherwise you just get what the compiler does by default, which works fine in some cases and not as well in others.
Architecture flags will automatically propagate to your project via transitive CMake properties. Kokkos does not currently support enabling multiple GPU architectures at the same time. The reason for this is that there is actually some internal stuff that changes host implementation based on the architecture specification. If you do not provide an architecture, Kokkos tries to identify the correct architecture for the GPU devices that are visible, but it is better to specify it yourself.
Kokkos is a C++ portability layer, but CUDA is usually built as a separate language with a separate compiler nvcc. nvcc does not accept all of the standard C++ compiler flags. Kokkos’s solution is to provide a nvcc_wrapper script that converts nvcc into a full C++ compiler.
cmake ${KOKKOS_SRC}
-DCMAKE_CXX_COMPILER=${KOKKOS_SRC}/bin/nvcc_wrapper
-DKOKKOS_ENABLE_CUDA=ONConfusingly, CMake will still tell you that it is using the host compiler, but don’t worry about that. One alternative to this is to just use clang++ as your compiler, since it understands CUDA.
To build your project against a Kokkos installation, we find the exported Kokkos configuration and generate the project’s build system accordingly:
#CMakeLists.txt
cmake_minimum_required(VERSION 3.12)
project(myProject CXX) # C++ needed to build my project
find_package(Kokkos REQUIRED) # fail if Kokkos not found
# build my executable
add_executable(myExe source.cpp)
# declare dependency on Kokkos
target_link_libraries(myExe PRIVATE Kokkos::kokkos)To make sure the find_package works, you set the cmake prefix path or pass -DKokkos_ROOT in the cmake configure command.
Exercise#
Now let’s introduce a very basic exercise that we will come back throughout the tutorial: take the inner product \( < y, A * x > \) where \( y \) is \( N \cross 1 \) , \( A \) is \( N \cross M \) and \( x \) is \( M \cross 1 \).
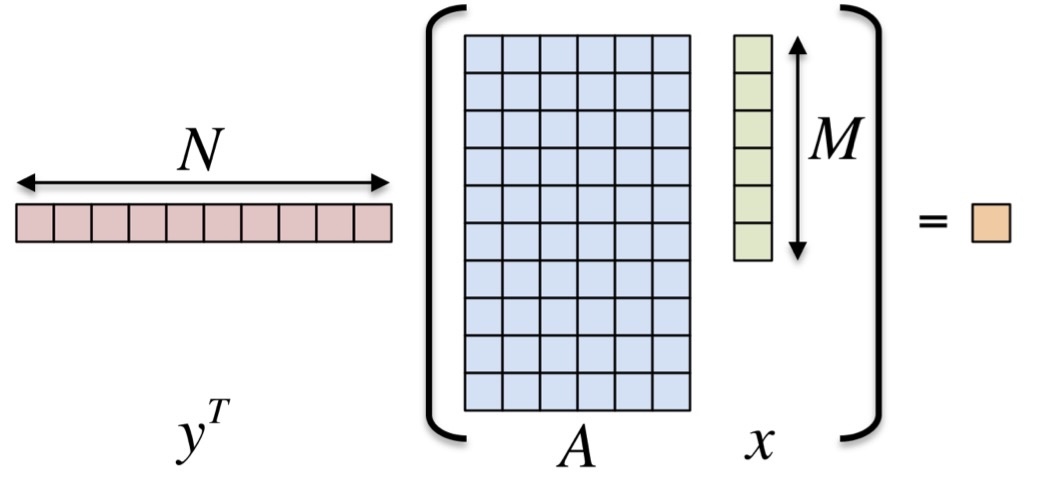
We want to parallelize the outer loop of this operation using Kokkos. We start with a host-serial implementation that looks like this:
//@HEADER
// ************************************************************************
//
// Kokkos v. 4.0
// Copyright (2022) National Technology & Engineering
// Solutions of Sandia, LLC (NTESS).
//
// Under the terms of Contract DE-NA0003525 with NTESS,
// the U.S. Government retains certain rights in this software.
//
// Part of Kokkos, under the Apache License v2.0 with LLVM Exceptions.
// See https://kokkos.org/LICENSE for license information.
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
//
//@HEADER
// EXERCISE 1 Goal:
// Use Kokkos to parallelize the outer loop of <y,Ax> using Kokkos::parallel_reduce.
#include <limits>
#include <cmath>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <chrono>
// EXERCISE: Include Kokkos_Core.hpp.
// cmath library unnecessary after.
// #include <Kokkos_Core.hpp>
void checkSizes( int &N, int &M, int &S, int &nrepeat );
int main( int argc, char* argv[] )
{
int N = -1; // number of rows 2^12
int M = -1; // number of columns 2^10
int S = -1; // total size 2^22
int nrepeat = 100; // number of repeats of the test
// Read command line arguments.
for ( int i = 0; i < argc; i++ ) {
if ( ( strcmp( argv[ i ], "-N" ) == 0 ) || ( strcmp( argv[ i ], "-Rows" ) == 0 ) ) {
N = pow( 2, atoi( argv[ ++i ] ) );
printf( " User N is %d\n", N );
}
else if ( ( strcmp( argv[ i ], "-M" ) == 0 ) || ( strcmp( argv[ i ], "-Columns" ) == 0 ) ) {
M = pow( 2, atof( argv[ ++i ] ) );
printf( " User M is %d\n", M );
}
else if ( ( strcmp( argv[ i ], "-S" ) == 0 ) || ( strcmp( argv[ i ], "-Size" ) == 0 ) ) {
S = pow( 2, atof( argv[ ++i ] ) );
printf( " User S is %d\n", S );
}
else if ( strcmp( argv[ i ], "-nrepeat" ) == 0 ) {
nrepeat = atoi( argv[ ++i ] );
}
else if ( ( strcmp( argv[ i ], "-h" ) == 0 ) || ( strcmp( argv[ i ], "-help" ) == 0 ) ) {
printf( " y^T*A*x Options:\n" );
printf( " -Rows (-N) <int>: exponent num, determines number of rows 2^num (default: 2^12 = 4096)\n" );
printf( " -Columns (-M) <int>: exponent num, determines number of columns 2^num (default: 2^10 = 1024)\n" );
printf( " -Size (-S) <int>: exponent num, determines total matrix size 2^num (default: 2^22 = 4096*1024 )\n" );
printf( " -nrepeat <int>: number of repetitions (default: 100)\n" );
printf( " -help (-h): print this message\n\n" );
exit( 1 );
}
}
// Check sizes.
checkSizes( N, M, S, nrepeat );
// EXERCISE: Initialize Kokkos runtime.
// Include braces to encapsulate code between initialize and finalize calls
// Kokkos::initialize( argc, argv );
// {
// For the sake of simplicity in this exercise, we're using std::malloc directly, but
// later on we'll learn a better way, so generally don't do this in Kokkos programs.
// Allocate y, x vectors and Matrix A:
// EXERCISE: For the impatient only: replace std::malloc with Kokkos::kokkos_malloc<>
// This would enable running on GPUs, if KOKKOS_LAMBDA is used instead of [=]
// as capture clause for all lambdas. It will be properly introduced later.
auto y = static_cast<double*>(std::malloc(N * sizeof(double)));
auto x = static_cast<double*>(std::malloc(M * sizeof(double)));
auto A = static_cast<double*>(std::malloc(N * M * sizeof(double)));
// Initialize y vector.
// EXERCISE: Convert outer loop to Kokkos::parallel_for.
for ( int i = 0; i < N; ++i ) {
y[ i ] = 1;
}
// Initialize x vector.
// EXERCISE: Convert outer loop to Kokkos::parallel_for.
for ( int i = 0; i < M; ++i ) {
x[ i ] = 1;
}
// Initialize A matrix, note 2D indexing computation.
// EXERCISE: Convert outer loop to Kokkos::parallel_for.
for ( int j = 0; j < N; ++j ) {
for ( int i = 0; i < M; ++i ) {
A[ j * M + i ] = 1;
}
}
// Timer products.
//Kokkos::Timer timer;
auto start = std::chrono::high_resolution_clock::now();
for ( int repeat = 0; repeat < nrepeat; repeat++ ) {
// Application: <y,Ax> = y^T*A*x
double result = 0;
// EXERCISE: Convert outer loop to Kokkos::parallel_reduce.
for ( int j = 0; j < N; ++j ) {
double temp2 = 0;
for ( int i = 0; i < M; ++i ) {
temp2 += A[ j * M + i ] * x[ i ];
}
result += y[ j ] * temp2;
}
// Output result.
if ( repeat == ( nrepeat - 1 ) ) {
printf( " Computed result for %d x %d is %lf\n", N, M, result );
}
const double solution = (double) N * (double) M;
if ( result != solution ) {
printf( " Error: result( %lf ) != solution( %lf )\n", result, solution );
}
}
// Calculate time.
//double time = timer.seconds();
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> time = end - start;
// Calculate bandwidth.
// Each matrix A row (each of length M) is read once.
// The x vector (of length M) is read N times.
// The y vector (of length N) is read once.
// double Gbytes = 1.0e-9 * double( sizeof(double) * ( 2 * M * N + N ) );
double Gbytes = 1.0e-9 * double( sizeof(double) * ( M + M * N + N ) );
// Print results (problem size, time and bandwidth in GB/s).
printf( " N( %d ) M( %d ) nrepeat ( %d ) problem( %g MB ) time( %g s ) bandwidth( %g GB/s )\n",
N, M, nrepeat, Gbytes * 1000, time.count(), Gbytes* nrepeat / time.count());
std::free(A);
std::free(y);
std::free(x);
// EXERCISE: finalize Kokkos runtime
// }
// Kokkos::finalize();
return 0;
}
void checkSizes( int &N, int &M, int &S, int &nrepeat ) {
// If S is undefined and N or M is undefined, set S to 2^22 or the bigger of N and M.
if ( S == -1 && ( N == -1 || M == -1 ) ) {
S = pow( 2, 22 );
if ( S < N ) S = N;
if ( S < M ) S = M;
}
// If S is undefined and both N and M are defined, set S = N * M.
if ( S == -1 ) S = N * M;
// If both N and M are undefined, fix row length to the smaller of S and 2^10 = 1024.
if ( N == -1 && M == -1 ) {
if ( S > 1024 ) {
M = 1024;
}
else {
M = S;
}
}
// If only M is undefined, set it.
if ( M == -1 ) M = S / N;
// If N is undefined, set it.
if ( N == -1 ) N = S / M;
printf( " Total size S = %d N = %d M = %d\n", S, N, M );
// Check sizes.
if ( ( S < 0 ) || ( N < 0 ) || ( M < 0 ) || ( nrepeat < 0 ) ) {
printf( " Sizes must be greater than 0.\n" );
exit( 1 );
}
if ( ( N * M ) != S ) {
printf( " N * M != S\n" );
exit( 1 );
}
}The first step in using Kokkos is to include, initialize, and finalize. This is similar to using MPI. In fact in practice you do this right after initializing MPI and right before finalizing MPI.
#include <Kokkos_Core.hpp>
int main(int argc, char* argv[]) {
/* ... do any necessary setup (e.g. initialize MPI) */
Kokkos::initialize(argc, argv);
{
/* ... do computations */
}
Kokkos::finalize();
return 0;
}Initialization accepts command-line arguments or environment variables:
--kokkos-threads=INT or KOKKOS_NUM_THREADS | total number of threads |
--kokkos-device-id=INT or KOKKOS_DEVICE_ID | device (GPU) ID to use |
Of course, we also honor the underlying settings such as OMP_NUM_THREADS for OpenMP or CUDA_VISIBLE_DEVICES for CUDA.
In this exercise we are using malloc directly to initialize, but in the next section we will introduce a better way (Kokkos::View).
// Allocate y, x vectors and Matrix A:
auto y = static_cast<double*>(std::malloc(N * sizeof(double)));
auto x = static_cast<double*>(std::malloc(M * sizeof(double)));
auto A = static_cast<double*>(std::malloc(N * M * sizeof(double)));
// Initialize y vector.
Kokkos::parallel_for( "y_init", N, KOKKOS_LAMBDA ( int i ) {
y[ i ] = 1;
});
// Initialize x vector.
Kokkos::parallel_for( "x_init", M, KOKKOS_LAMBDA ( int i ) {
x[ i ] = 1;
});
// Initialize A matrix, note 2D indexing computation.
Kokkos::parallel_for( "matrix_init", N, KOKKOS_LAMBDA ( int j ) {
for ( int i = 0; i < M; ++i ) {
A[ j * M + i ] = 1;
}
});We can make use of Kokkos::Timer instead of std::chrono::high_resolution_clock
Kokkos::Timer timer;
/* parallel work */
double time = timer.seconds();Finally we parallelize the loop body using Kokkos::parallel_reduce
for ( int repeat = 0; repeat < nrepeat; repeat++ ) {
// Application: <y,Ax> = y^T*A*x
double result = 0;
Kokkos::parallel_reduce( "yAx", N, KOKKOS_LAMBDA ( int j, double &update ) {
double temp2 = 0;
for ( int i = 0; i < M; ++i ) {
temp2 += A[ j * M + i ] * x[ i ];
}
update += y[ j ] * temp2;
}, result );
// Output result.
if ( repeat == ( nrepeat - 1 ) ) {
printf( " Computed result for %d x %d is %lf\n", N, M, result );
}
const double solution = (double) N * (double) M;
if ( result != solution ) {
printf( " Error: result( %lf ) != solution( %lf )\n", result, solution );
}
}The final result looks like this:
//@HEADER
// ************************************************************************
//
// Kokkos v. 4.0
// Copyright (2022) National Technology & Engineering
// Solutions of Sandia, LLC (NTESS).
//
// Under the terms of Contract DE-NA0003525 with NTESS,
// the U.S. Government retains certain rights in this software.
//
// Part of Kokkos, under the Apache License v2.0 with LLVM Exceptions.
// See https://kokkos.org/LICENSE for license information.
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
//
//@HEADER
#include <limits>
#include <cmath>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <Kokkos_Core.hpp>
void checkSizes( int &N, int &M, int &S, int &nrepeat );
int main( int argc, char* argv[] )
{
int N = -1; // number of rows 2^12
int M = -1; // number of columns 2^10
int S = -1; // total size 2^22
int nrepeat = 100; // number of repeats of the test
// Read command line arguments.
for ( int i = 0; i < argc; i++ ) {
if ( ( strcmp( argv[ i ], "-N" ) == 0 ) || ( strcmp( argv[ i ], "-Rows" ) == 0 ) ) {
N = pow( 2, atoi( argv[ ++i ] ) );
printf( " User N is %d\n", N );
}
else if ( ( strcmp( argv[ i ], "-M" ) == 0 ) || ( strcmp( argv[ i ], "-Columns" ) == 0 ) ) {
M = pow( 2, atof( argv[ ++i ] ) );
printf( " User M is %d\n", M );
}
else if ( ( strcmp( argv[ i ], "-S" ) == 0 ) || ( strcmp( argv[ i ], "-Size" ) == 0 ) ) {
S = pow( 2, atof( argv[ ++i ] ) );
printf( " User S is %d\n", S );
}
else if ( strcmp( argv[ i ], "-nrepeat" ) == 0 ) {
nrepeat = atoi( argv[ ++i ] );
}
else if ( ( strcmp( argv[ i ], "-h" ) == 0 ) || ( strcmp( argv[ i ], "-help" ) == 0 ) ) {
printf( " y^T*A*x Options:\n" );
printf( " -Rows (-N) <int>: exponent num, determines number of rows 2^num (default: 2^12 = 4096)\n" );
printf( " -Columns (-M) <int>: exponent num, determines number of columns 2^num (default: 2^10 = 1024)\n" );
printf( " -Size (-S) <int>: exponent num, determines total matrix size 2^num (default: 2^22 = 4096*1024 )\n" );
printf( " -nrepeat <int>: number of repetitions (default: 100)\n" );
printf( " -help (-h): print this message\n\n" );
exit( 1 );
}
}
// Check sizes.
checkSizes( N, M, S, nrepeat );
Kokkos::initialize( argc, argv );
{
// For the sake of simplicity in this exercise, we're using std::malloc directly, but
// later on we'll learn a better way, so generally don't do this in Kokkos programs.
// Allocate y, x vectors and Matrix A:
auto y = static_cast<double*>(std::malloc(N * sizeof(double)));
auto x = static_cast<double*>(std::malloc(M * sizeof(double)));
auto A = static_cast<double*>(std::malloc(N * M * sizeof(double)));
// Initialize y vector.
Kokkos::parallel_for( "y_init", N, KOKKOS_LAMBDA ( int i ) {
y[ i ] = 1;
});
// Initialize x vector.
Kokkos::parallel_for( "x_init", M, KOKKOS_LAMBDA ( int i ) {
x[ i ] = 1;
});
// Initialize A matrix, note 2D indexing computation.
Kokkos::parallel_for( "matrix_init", N, KOKKOS_LAMBDA ( int j ) {
for ( int i = 0; i < M; ++i ) {
A[ j * M + i ] = 1;
}
});
// Timer products.
Kokkos::Timer timer;
for ( int repeat = 0; repeat < nrepeat; repeat++ ) {
// Application: <y,Ax> = y^T*A*x
double result = 0;
Kokkos::parallel_reduce( "yAx", N, KOKKOS_LAMBDA ( int j, double &update ) {
double temp2 = 0;
for ( int i = 0; i < M; ++i ) {
temp2 += A[ j * M + i ] * x[ i ];
}
update += y[ j ] * temp2;
}, result );
// Output result.
if ( repeat == ( nrepeat - 1 ) ) {
printf( " Computed result for %d x %d is %lf\n", N, M, result );
}
const double solution = (double) N * (double) M;
if ( result != solution ) {
printf( " Error: result( %lf ) != solution( %lf )\n", result, solution );
}
}
double time = timer.seconds();
// Calculate bandwidth.
// Each matrix A row (each of length M) is read once.
// The x vector (of length M) is read N times.
// The y vector (of length N) is read once.
// double Gbytes = 1.0e-9 * double( sizeof(double) * ( 2 * M * N + N ) );
double Gbytes = 1.0e-9 * double( sizeof(double) * ( M + M * N + N ) );
// Print results (problem size, time and bandwidth in GB/s).
printf( " N( %d ) M( %d ) nrepeat ( %d ) problem( %g MB ) time( %g s ) bandwidth( %g GB/s )\n",
N, M, nrepeat, Gbytes * 1000, time, Gbytes * nrepeat / time );
std::free(A);
std::free(y);
std::free(x);
}
Kokkos::finalize();
return 0;
}
void checkSizes( int &N, int &M, int &S, int &nrepeat ) {
// If S is undefined and N or M is undefined, set S to 2^22 or the bigger of N and M.
if ( S == -1 && ( N == -1 || M == -1 ) ) {
S = pow( 2, 22 );
if ( S < N ) S = N;
if ( S < M ) S = M;
}
// If S is undefined and both N and M are defined, set S = N * M.
if ( S == -1 ) S = N * M;
// If both N and M are undefined, fix row length to the smaller of S and 2^10 = 1024.
if ( N == -1 && M == -1 ) {
if ( S > 1024 ) {
M = 1024;
}
else {
M = S;
}
}
// If only M is undefined, set it.
if ( M == -1 ) M = S / N;
// If N is undefined, set it.
if ( N == -1 ) N = S / M;
printf( " Total size S = %d N = %d M = %d\n", S, N, M );
// Check sizes.
if ( ( S < 0 ) || ( N < 0 ) || ( M < 0 ) || ( nrepeat < 0 ) ) {
printf( " Sizes must be greater than 0.\n" );
exit( 1 );
}
if ( ( N * M ) != S ) {
printf( " N * M != S\n" );
exit( 1 );
}
}With that, we can actually run the example and see what it does.
./build/01_Exercise
Total size S = 4194304 N = 4096 M = 1024
Kokkos::OpenMP::initialize WARNING: OMP_PROC_BIND environment variable not set
In general, for best performance with OpenMP 4.0 or better set OMP_PROC_BIND=spread and OMP_PLACES=threads
For best performance with OpenMP 3.1 set OMP_PROC_BIND=true
For unit testing set OMP_PROC_BIND=false
Computed result for 4096 x 1024 is 4194304.000000
N( 4096 ) M( 1024 ) nrepeat ( 100 ) problem( 33.5954 MB ) time( 0.106427 s ) bandwidth( 31.5666 GB/s )We first set the OpenMP thread binding settings to the suggested environment variables
set -gx OMP_PROC_BIND spread; set -gx OMP_PLACES threads
./build/01_Exercise
Total size S = 4194304 N = 4096 M = 1024
Computed result for 4096 x 1024 is 4194304.000000
N( 4096 ) M( 1024 ) nrepeat ( 100 ) problem( 33.5954 MB ) time( 0.101779 s ) bandwidth( 33.0081 GB/s )On this machine, there is very little difference because of the small number of cores on my little macbook air, but on a machine with a different core configuration this can make a very big difference. This is a memory-bound computation, so the speed we get really just depends on whether we are running out of the cache. If we increase the problem size so that it no longer fits in cache, we can see the memory bandwidth drop
./build/01_Exercise -S 25
User S is 33554432
Total size S = 33554432 N = 32768 M = 1024
Computed result for 32768 x 1024 is 33554432.000000
N( 32768 ) M( 1024 ) nrepeat ( 100 ) problem( 268.706 MB ) time( 0.600796 s ) bandwidth( 44.725 GB/s )
./build/01_Exercise -S 28
User S is 268435456
Total size S = 268435456 N = 262144 M = 1024
Computed result for 262144 x 1024 is 268435456.000000
N( 262144 ) M( 1024 ) nrepeat ( 100 ) problem( 2149.59 MB ) time( 48.2423 s ) bandwidth( 4.45582 GB/s )