Uri mentioned a project by David Beckingsale at LLNL called “Apollo” that attempts to tune kernel parameters at runtime in order to optimize for the available hardware. It’s especially for codes with adaptive capabalities (like adaptive mesh refinement) in which the runtime characteristics of the compute kernels tend to be very input dependent.
This is the main paper they put out: https://computing.llnl.gov/sites/default/files/Apollo-Fast-Lightweight-Dynamic-Tuning-Data-Dependent-Code-LLNL-paper_0.pdf
And here’s the github repository: https://github.com/LLNL/apollo
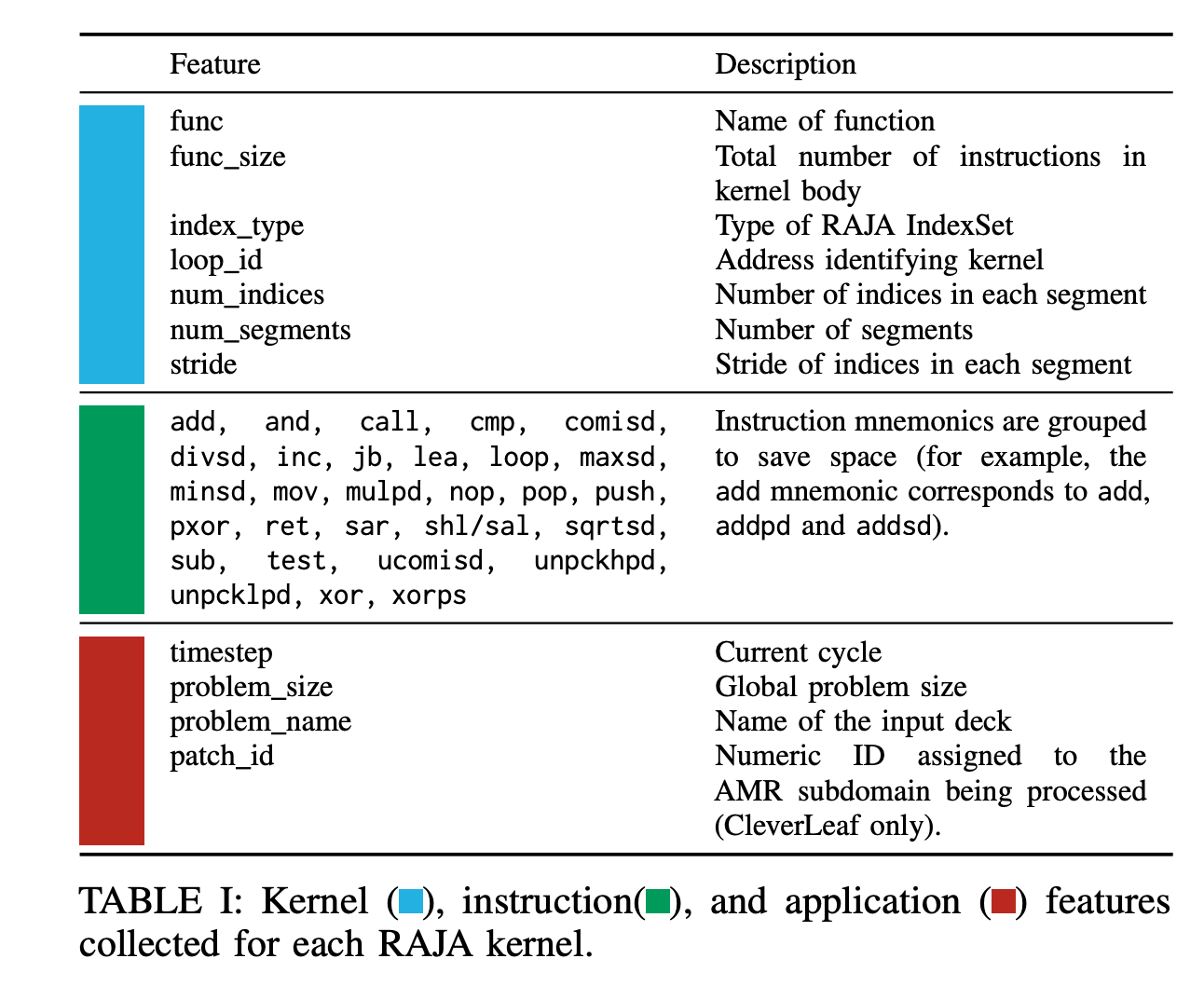
The approach they take is: At runtime, for each kernel execution apollo collects the runtime and a “feature vector” describing various features of the kernel. These features include:
- Parameters passed to the RAJA
forall - Instruction features gathered from the kernel body
- Runtime measurements
- Optional features specified by the developer
To be able to change the execution policy at runtime (which is generally not possible in RAJA), they added a RAJA extension
I’d really like to see it in action, so let’s see if we can get a simple project using their framework to compile. We can eventually get Claude to spit out something like this:
#include <iostream>
#include <iomanip>
#include <vector>
#include <memory>
#include <cmath>
#include <chrono>
#include <algorithm>
#include <numeric>
#include <random>
#include <cstring>
#include <thread>
#include "RAJA/RAJA.hpp"
#include "apollo/Apollo.h"
#include "apollo/Region.h"
#include "kernels.h"
// Define execution policies for CPU
using sequential_policy = RAJA::seq_exec;
#ifdef RAJA_ENABLE_OPENMP
using omp_policy_1 = RAJA::omp_parallel_for_exec;
using omp_policy_static = RAJA::omp_parallel_for_static_exec<16>;
using omp_policy_dynamic = RAJA::omp_parallel_for_dynamic_exec<8>;
using omp_policy_guided = RAJA::omp_parallel_for_guided_exec<>;
// Policy list for Apollo to choose from
using CPUPolicyList = RAJA::list<
sequential_policy,
omp_policy_1,
omp_policy_static,
omp_policy_dynamic,
omp_policy_guided
>;
constexpr int NUM_POLICIES = 5;
const char* policy_names[] = {
"Sequential",
"OpenMP Default",
"OpenMP Static-16",
"OpenMP Dynamic-8",
"OpenMP Guided"
};
#else
// If OpenMP is not available, use only sequential
using CPUPolicyList = RAJA::list<sequential_policy>;
constexpr int NUM_POLICIES = 1;
const char* policy_names[] = {"Sequential"};
#endif
namespace apollo_demo {
// Timer utility
class Timer {
private:
std::chrono::high_resolution_clock::time_point start_time;
std::chrono::high_resolution_clock::time_point end_time;
public:
void start() {
start_time = std::chrono::high_resolution_clock::now();
}
void stop() {
end_time = std::chrono::high_resolution_clock::now();
}
double getElapsedMilliseconds() const {
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end_time - start_time);
return duration.count() / 1000.0;
}
};
// Benchmark runner for a specific kernel
class KernelBenchmark {
private:
std::unique_ptr<KernelBase> kernel;
Apollo::Region* region;
std::string kernel_name;
bool use_apollo;
public:
KernelBenchmark(const std::string& name, bool enable_apollo = true)
: kernel_name(name), use_apollo(enable_apollo), region(nullptr) {
kernel = createKernel(name);
if (!kernel) {
throw std::runtime_error("Unknown kernel: " + name);
}
if (use_apollo) {
// Create Apollo region with 5 features (from KernelFeatures)
region = new Apollo::Region(
5, // number of features
kernel->getName(),
NUM_POLICIES,
50 // minimum training data before making predictions
);
}
}
~KernelBenchmark() {
if (region) delete region;
cleanup();
}
void cleanup() {
if (region) {
delete region;
region = nullptr;
}
}
template<typename KernelType>
double runWithApollo(KernelType* k, const ProblemConfig& config) {
if (!region) {
throw std::runtime_error("Apollo not enabled for this benchmark");
}
// Extract features for Apollo
KernelFeatures features = k->extractFeatures(config);
std::vector<float> feature_vec = features.toVector();
// Start Apollo region
Apollo::RegionContext* context = region->begin(feature_vec);
// Get policy recommendation from Apollo
int policy_idx = region->getPolicyIndex(context);
Timer timer;
timer.start();
// Execute with selected policy
switch(policy_idx) {
case 0:
k->template execute<sequential_policy>();
break;
#ifdef RAJA_ENABLE_OPENMP
case 1:
k->template execute<omp_policy_1>();
break;
case 2:
k->template execute<omp_policy_static>();
break;
case 3:
k->template execute<omp_policy_dynamic>();
break;
case 4:
k->template execute<omp_policy_guided>();
break;
#endif
default:
k->template execute<sequential_policy>();
break;
}
timer.stop();
double elapsed = timer.getElapsedMilliseconds();
// End Apollo region with performance metric
region->end(context, elapsed);
if (policy_idx >= 0 && policy_idx < NUM_POLICIES) {
std::cout << " Apollo selected: " << policy_names[policy_idx]
<< " (policy " << policy_idx << ")" << std::endl;
}
return elapsed;
}
template<typename KernelType, typename ExecPolicy>
double runWithPolicy(KernelType* k) {
Timer timer;
timer.start();
k->template execute<ExecPolicy>();
timer.stop();
return timer.getElapsedMilliseconds();
}
void runBenchmark(const ProblemConfig& config, int iterations = 10) {
std::cout << "\n=== Running " << kernel_name << " Kernel ===" << std::endl;
std::cout << "Problem size: " << config.size << std::endl;
std::cout << "Iterations: " << iterations << std::endl;
kernel->initialize(config);
std::vector<double> times;
for (int iter = 0; iter < iterations; ++iter) {
double elapsed = 0.0;
if (use_apollo) {
if (auto* k = dynamic_cast<VectorAddKernel*>(kernel.get())) {
elapsed = runWithApollo(k, config);
} else if (auto* k = dynamic_cast<DaxpyKernel*>(kernel.get())) {
elapsed = runWithApollo(k, config);
} else if (auto* k = dynamic_cast<MatVecKernel*>(kernel.get())) {
elapsed = runWithApollo(k, config);
} else if (auto* k = dynamic_cast<Stencil1DKernel*>(kernel.get())) {
elapsed = runWithApollo(k, config);
} else if (auto* k = dynamic_cast<ReductionKernel*>(kernel.get())) {
elapsed = runWithApollo(k, config);
} else if (auto* k = dynamic_cast<SpMVKernel*>(kernel.get())) {
elapsed = runWithApollo(k, config);
} else if (auto* k = dynamic_cast<IndirectKernel*>(kernel.get())) {
elapsed = runWithApollo(k, config);
}
} else {
// Run with default policy (sequential)
if (auto* k = dynamic_cast<VectorAddKernel*>(kernel.get())) {
elapsed = runWithPolicy<VectorAddKernel, sequential_policy>(k);
} else if (auto* k = dynamic_cast<DaxpyKernel*>(kernel.get())) {
elapsed = runWithPolicy<DaxpyKernel, sequential_policy>(k);
} else if (auto* k = dynamic_cast<MatVecKernel*>(kernel.get())) {
elapsed = runWithPolicy<MatVecKernel, sequential_policy>(k);
} else if (auto* k = dynamic_cast<Stencil1DKernel*>(kernel.get())) {
elapsed = runWithPolicy<Stencil1DKernel, sequential_policy>(k);
} else if (auto* k = dynamic_cast<ReductionKernel*>(kernel.get())) {
elapsed = runWithPolicy<ReductionKernel, sequential_policy>(k);
} else if (auto* k = dynamic_cast<SpMVKernel*>(kernel.get())) {
elapsed = runWithPolicy<SpMVKernel, sequential_policy>(k);
} else if (auto* k = dynamic_cast<IndirectKernel*>(kernel.get())) {
elapsed = runWithPolicy<IndirectKernel, sequential_policy>(k);
}
}
times.push_back(elapsed);
std::cout << " Iteration " << std::setw(2) << iter + 1
<< ": " << std::fixed << std::setprecision(3)
<< elapsed << " ms" << std::endl;
}
// Compute statistics
double avg_time = std::accumulate(times.begin(), times.end(), 0.0) / times.size();
double min_time = *std::min_element(times.begin(), times.end());
double max_time = *std::max_element(times.begin(), times.end());
std::cout << "\nStatistics:" << std::endl;
std::cout << " Average: " << std::fixed << std::setprecision(3) << avg_time << " ms" << std::endl;
std::cout << " Min: " << std::fixed << std::setprecision(3) << min_time << " ms" << std::endl;
std::cout << " Max: " << std::fixed << std::setprecision(3) << max_time << " ms" << std::endl;
kernel->cleanup();
}
void trainApollo(int step) {
if (region) {
region->train(step);
std::cout << "Apollo training triggered at step " << step << std::endl;
}
}
void cleanupRegion() {
cleanup();
}
};
// Scenario runner - runs different problem configurations
class ScenarioRunner {
private:
Apollo* apollo;
bool verbose;
public:
ScenarioRunner(bool verbose_mode = false)
: apollo(Apollo::instance()), verbose(verbose_mode) {}
void runAdaptiveScenario() {
std::cout << "\n" << std::string(60, '=') << std::endl;
std::cout << "ADAPTIVE SCENARIO: Apollo learns optimal policies" << std::endl;
std::cout << std::string(60, '=') << std::endl;
// Create benchmarks for different kernels
std::vector<std::unique_ptr<KernelBenchmark>> benchmarks;
benchmarks.push_back(std::make_unique<KernelBenchmark>("VectorAdd", true));
benchmarks.push_back(std::make_unique<KernelBenchmark>("DAXPY", true));
benchmarks.push_back(std::make_unique<KernelBenchmark>("Stencil1D", true));
benchmarks.push_back(std::make_unique<KernelBenchmark>("Reduction", true));
// Different problem configurations to test adaptation
std::vector<ProblemConfig> configs;
// Small problems
ProblemConfig small_config;
small_config.size = 10000;
small_config.iterations = 5;
configs.push_back(small_config);
// Medium problems
ProblemConfig medium_config;
medium_config.size = 100000;
medium_config.iterations = 5;
configs.push_back(medium_config);
// Large problems
ProblemConfig large_config;
large_config.size = 1000000;
large_config.iterations = 5;
configs.push_back(large_config);
// Very large problems
ProblemConfig xlarge_config;
xlarge_config.size = 10000000;
xlarge_config.iterations = 5;
configs.push_back(xlarge_config);
int global_step = 0;
// Run exploration phase
std::cout << "\n--- EXPLORATION PHASE ---" << std::endl;
std::cout << "Apollo explores different policies..." << std::endl;
for (size_t config_idx = 0; config_idx < 2; ++config_idx) {
for (auto& benchmark : benchmarks) {
benchmark->runBenchmark(configs[config_idx], 5);
global_step++;
}
}
// Trigger training
std::cout << "\n--- TRAINING PHASE ---" << std::endl;
apollo->train(0);
std::cout << "Apollo has trained models based on exploration data" << std::endl;
// Run exploitation phase
std::cout << "\n--- EXPLOITATION PHASE ---" << std::endl;
std::cout << "Apollo uses learned models to select optimal policies..." << std::endl;
for (size_t config_idx = 2; config_idx < configs.size(); ++config_idx) {
for (auto& benchmark : benchmarks) {
benchmark->runBenchmark(configs[config_idx], 5);
global_step++;
// Periodically retrain to adapt
if (global_step % 10 == 0) {
apollo->train(global_step / 10);
}
}
}
// Clean up benchmarks explicitly
for (auto& benchmark : benchmarks) {
benchmark->cleanupRegion();
}
benchmarks.clear();
}
void runComparisonScenario() {
std::cout << "\n" << std::string(60, '=') << std::endl;
std::cout << "COMPARISON SCENARIO: Apollo vs Fixed Policies" << std::endl;
std::cout << std::string(60, '=') << std::endl;
ProblemConfig config;
config.size = 5000000;
config.iterations = 20;
std::cout << "\n--- Running with Apollo (adaptive) ---" << std::endl;
KernelBenchmark apollo_bench("VectorAdd", true);
apollo_bench.runBenchmark(config, 20);
// Train after exploration
apollo->train(1);
std::cout << "\n--- Running with Apollo (after training) ---" << std::endl;
apollo_bench.runBenchmark(config, 10);
// Clean up benchmark
apollo_bench.cleanupRegion();
#ifdef RAJA_ENABLE_OPENMP
std::cout << "\n--- Running with fixed Sequential policy ---" << std::endl;
KernelBenchmark seq_bench("VectorAdd", false);
seq_bench.runBenchmark(config, 10);
seq_bench.cleanupRegion();
#endif
}
void runDataDependentScenario() {
std::cout << "\n" << std::string(60, '=') << std::endl;
std::cout << "DATA-DEPENDENT SCENARIO: Apollo adapts to data patterns" << std::endl;
std::cout << std::string(60, '=') << std::endl;
KernelBenchmark spmv_bench("SpMV", true);
KernelBenchmark indirect_bench("Indirect", true);
// Test with different sparsity levels
std::vector<double> sparsity_levels = {0.01, 0.1, 0.5, 0.9, 0.99};
for (double sparsity : sparsity_levels) {
std::cout << "\n--- Sparsity Level: " << (sparsity * 100) << "% ---" << std::endl;
ProblemConfig config;
config.size = 100000;
config.sparsity = sparsity;
config.iterations = 5;
spmv_bench.runBenchmark(config, 10);
// Train after each sparsity level
apollo->train(static_cast<int>(sparsity * 100));
}
// Clean up benchmarks
spmv_bench.cleanupRegion();
// Test with different access patterns
std::cout << "\n--- Testing Indirect Access Patterns ---" << std::endl;
ProblemConfig seq_config;
seq_config.size = 1000000;
seq_config.use_indirect = false;
seq_config.iterations = 5;
ProblemConfig rand_config;
rand_config.size = 1000000;
rand_config.use_indirect = true;
rand_config.iterations = 5;
std::cout << "\nSequential access pattern:" << std::endl;
indirect_bench.runBenchmark(seq_config, 10);
std::cout << "\nRandom access pattern:" << std::endl;
indirect_bench.runBenchmark(rand_config, 10);
// Clean up benchmark
indirect_bench.cleanupRegion();
}
};
} // namespace apollo_demo
// Main function
int main(int argc, char** argv) {
std::cout << "Apollo-RAJA CPU Demonstration" << std::endl;
std::cout << "==============================" << std::endl;
// Print configuration
std::cout << "\nConfiguration:" << std::endl;
std::cout << " Number of policies: " << NUM_POLICIES << std::endl;
std::cout << " Available policies:" << std::endl;
for (int i = 0; i < NUM_POLICIES; ++i) {
std::cout << " " << i << ": " << policy_names[i] << std::endl;
}
#ifdef RAJA_ENABLE_OPENMP
int num_threads = 1;
#pragma omp parallel
{
#pragma omp single
num_threads = omp_get_num_threads();
}
std::cout << " OpenMP threads: " << num_threads << std::endl;
#else
std::cout << " OpenMP: DISABLED" << std::endl;
#endif
// Check for Apollo environment variables
const char* policy_model = std::getenv("APOLLO_POLICY_MODEL");
if (policy_model) {
std::cout << " Apollo Policy Model: " << policy_model << std::endl;
} else {
std::cout << " Apollo Policy Model: Default (Static)" << std::endl;
std::cout << " Tip: Set APOLLO_POLICY_MODEL env var to enable tuning" << std::endl;
std::cout << " Example: APOLLO_POLICY_MODEL=DecisionTree,explore=RoundRobin,max_depth=4" << std::endl;
}
const char* train_period = std::getenv("APOLLO_GLOBAL_TRAIN_PERIOD");
if (train_period) {
std::cout << " Apollo Global Train Period: " << train_period << std::endl;
}
// Parse command line arguments
bool run_all = true;
bool run_adaptive = false;
bool run_comparison = false;
bool run_data_dependent = false;
for (int i = 1; i < argc; ++i) {
std::string arg(argv[i]);
if (arg == "--adaptive") {
run_all = false;
run_adaptive = true;
} else if (arg == "--comparison") {
run_all = false;
run_comparison = true;
} else if (arg == "--data-dependent") {
run_all = false;
run_data_dependent = true;
} else if (arg == "--help" || arg == "-h") {
std::cout << "\nUsage: " << argv[0] << " [options]" << std::endl;
std::cout << "Options:" << std::endl;
std::cout << " --adaptive Run adaptive scenario" << std::endl;
std::cout << " --comparison Run comparison scenario" << std::endl;
std::cout << " --data-dependent Run data-dependent scenario" << std::endl;
std::cout << " --help, -h Show this help message" << std::endl;
std::cout << "\nEnvironment variables:" << std::endl;
std::cout << " APOLLO_POLICY_MODEL Set Apollo tuning model" << std::endl;
std::cout << " APOLLO_GLOBAL_TRAIN_PERIOD Set automatic training period" << std::endl;
std::cout << " APOLLO_TRACE_CSV Enable CSV tracing (0/1)" << std::endl;
std::cout << " APOLLO_STORE_MODELS Store/load trained models (0/1)" << std::endl;
return 0;
}
}
// Create scenario runner
apollo_demo::ScenarioRunner runner(false);
// Run selected scenarios
if (run_all || run_adaptive) {
runner.runAdaptiveScenario();
}
if (run_all || run_comparison) {
runner.runComparisonScenario();
}
if (run_all || run_data_dependent) {
runner.runDataDependentScenario();
}
std::cout << "\n" << std::string(60, '=') << std::endl;
std::cout << "Apollo-RAJA CPU Demonstration Complete" << std::endl;
std::cout << std::string(60, '=') << std::endl;
// Give some time for cleanup
std::this_thread::sleep_for(std::chrono::milliseconds(100));
return 0;
}with a wide variety of compute kernels defined in kernels.h:
// kernels.h
//
#ifndef APOLLO_RAJA_DEMO_KERNELS_H
#define APOLLO_RAJA_DEMO_KERNELS_H
#include <vector>
#include <memory>
#include <cmath>
#include <algorithm>
#include "RAJA/RAJA.hpp"
namespace apollo_demo {
// Structure to hold problem configuration
struct ProblemConfig {
int size; // Problem size
int iterations; // Number of iterations
double sparsity; // Sparsity level (0.0 to 1.0)
int stencil_size; // Size of stencil pattern
bool use_indirect; // Use indirect access pattern
ProblemConfig()
: size(1000000), iterations(100), sparsity(0.0),
stencil_size(5), use_indirect(false) {}
};
// Features that Apollo can use for tuning decisions
struct KernelFeatures {
float problem_size_log; // Log of problem size
float memory_footprint; // Estimated memory footprint in MB
float arithmetic_intensity; // Ops per byte
float sparsity_level; // Sparsity of data (0-1)
float access_pattern; // 0 for sequential, 1 for random
KernelFeatures()
: problem_size_log(0), memory_footprint(0),
arithmetic_intensity(0), sparsity_level(0), access_pattern(0) {}
std::vector<float> toVector() const {
return {problem_size_log, memory_footprint, arithmetic_intensity,
sparsity_level, access_pattern};
}
};
// Base class for kernels
class KernelBase {
public:
virtual ~KernelBase() = default;
virtual const char* getName() const = 0;
virtual KernelFeatures extractFeatures(const ProblemConfig& config) const = 0;
virtual void initialize(const ProblemConfig& config) = 0;
virtual void cleanup() = 0;
};
// Vector addition kernel: c = a + b
class VectorAddKernel : public KernelBase {
private:
double* a;
double* b;
double* c;
int size;
public:
VectorAddKernel() : a(nullptr), b(nullptr), c(nullptr), size(0) {}
~VectorAddKernel() { cleanup(); }
const char* getName() const override { return "VectorAdd"; }
void initialize(const ProblemConfig& config) override;
void cleanup() override;
KernelFeatures extractFeatures(const ProblemConfig& config) const override;
template<typename ExecPolicy>
void execute() {
RAJA::forall<ExecPolicy>(RAJA::RangeSegment(0, size),
[=] RAJA_DEVICE (int i) {
c[i] = a[i] + b[i];
});
}
double* getResult() { return c; }
};
// DAXPY kernel: y = alpha * x + y
class DaxpyKernel : public KernelBase {
private:
double* x;
double* y;
double alpha;
int size;
public:
DaxpyKernel() : x(nullptr), y(nullptr), alpha(2.0), size(0) {}
~DaxpyKernel() { cleanup(); }
const char* getName() const override { return "DAXPY"; }
void initialize(const ProblemConfig& config) override;
void cleanup() override;
KernelFeatures extractFeatures(const ProblemConfig& config) const override;
template<typename ExecPolicy>
void execute() {
double a = alpha;
RAJA::forall<ExecPolicy>(RAJA::RangeSegment(0, size),
[=] RAJA_DEVICE (int i) {
y[i] = a * x[i] + y[i];
});
}
double* getResult() { return y; }
};
// Matrix-vector multiplication: y = A * x
class MatVecKernel : public KernelBase {
private:
double* A; // Matrix in row-major format
double* x; // Input vector
double* y; // Output vector
int rows;
int cols;
public:
MatVecKernel() : A(nullptr), x(nullptr), y(nullptr), rows(0), cols(0) {}
~MatVecKernel() { cleanup(); }
const char* getName() const override { return "MatVec"; }
void initialize(const ProblemConfig& config) override;
void cleanup() override;
KernelFeatures extractFeatures(const ProblemConfig& config) const override;
template<typename ExecPolicy>
void execute() {
RAJA::forall<ExecPolicy>(RAJA::RangeSegment(0, rows),
[=] RAJA_DEVICE (int i) {
double sum = 0.0;
for (int j = 0; j < cols; ++j) {
sum += A[i * cols + j] * x[j];
}
y[i] = sum;
});
}
double* getResult() { return y; }
};
// 1D Stencil computation
class Stencil1DKernel : public KernelBase {
private:
double* input;
double* output;
double* weights;
int size;
int stencil_radius;
public:
Stencil1DKernel() : input(nullptr), output(nullptr), weights(nullptr),
size(0), stencil_radius(2) {}
~Stencil1DKernel() { cleanup(); }
const char* getName() const override { return "Stencil1D"; }
void initialize(const ProblemConfig& config) override;
void cleanup() override;
KernelFeatures extractFeatures(const ProblemConfig& config) const override;
template<typename ExecPolicy>
void execute() {
int radius = stencil_radius;
RAJA::forall<ExecPolicy>(RAJA::RangeSegment(radius, size - radius),
[=] RAJA_DEVICE (int i) {
double sum = 0.0;
for (int j = -radius; j <= radius; ++j) {
sum += input[i + j] * weights[j + radius];
}
output[i] = sum;
});
}
double* getResult() { return output; }
};
// Reduction kernel: sum all elements
class ReductionKernel : public KernelBase {
private:
double* data;
int size;
double result;
public:
ReductionKernel() : data(nullptr), size(0), result(0.0) {}
~ReductionKernel() { cleanup(); }
const char* getName() const override { return "Reduction"; }
void initialize(const ProblemConfig& config) override;
void cleanup() override;
KernelFeatures extractFeatures(const ProblemConfig& config) const override;
template<typename ExecPolicy>
void execute() {
RAJA::ReduceSum<RAJA::seq_reduce, double> sum(0.0);
RAJA::forall<ExecPolicy>(RAJA::RangeSegment(0, size),
[=] RAJA_DEVICE (int i) {
sum += data[i];
});
result = sum.get();
}
double getResult() { return result; }
};
// Sparse matrix-vector multiplication
class SpMVKernel : public KernelBase {
private:
// CSR format
double* values; // Non-zero values
int* col_indices; // Column indices
int* row_ptr; // Row pointers
double* x; // Input vector
double* y; // Output vector
int num_rows;
int num_nonzeros;
public:
SpMVKernel() : values(nullptr), col_indices(nullptr), row_ptr(nullptr),
x(nullptr), y(nullptr), num_rows(0), num_nonzeros(0) {}
~SpMVKernel() { cleanup(); }
const char* getName() const override { return "SpMV"; }
void initialize(const ProblemConfig& config) override;
void cleanup() override;
KernelFeatures extractFeatures(const ProblemConfig& config) const override;
template<typename ExecPolicy>
void execute() {
RAJA::forall<ExecPolicy>(RAJA::RangeSegment(0, num_rows),
[=] RAJA_DEVICE (int row) {
double sum = 0.0;
for (int idx = row_ptr[row]; idx < row_ptr[row + 1]; ++idx) {
sum += values[idx] * x[col_indices[idx]];
}
y[row] = sum;
});
}
double* getResult() { return y; }
};
// Indirect memory access kernel (gather-scatter pattern)
class IndirectKernel : public KernelBase {
private:
double* src;
double* dst;
int* indices;
int size;
public:
IndirectKernel() : src(nullptr), dst(nullptr), indices(nullptr), size(0) {}
~IndirectKernel() { cleanup(); }
const char* getName() const override { return "Indirect"; }
void initialize(const ProblemConfig& config) override;
void cleanup() override;
KernelFeatures extractFeatures(const ProblemConfig& config) const override;
template<typename ExecPolicy>
void execute() {
RAJA::forall<ExecPolicy>(RAJA::RangeSegment(0, size),
[=] RAJA_DEVICE (int i) {
dst[i] = src[indices[i]] * 2.0;
});
}
double* getResult() { return dst; }
};
// Factory function to create kernels
std::unique_ptr<KernelBase> createKernel(const std::string& kernel_name);
// Utility functions
void initializeRandomData(double* data, int size, double min_val = 0.0, double max_val = 1.0);
void initializeRandomIndices(int* indices, int size, int max_index);
double computeChecksum(const double* data, int size);
} // namespace apollo_demo
#endif // APOLLO_RAJA_DEMO_KERNELS_H
// kernels.cpp
#include "kernels.h"
#include <cstring>
#include <random>
#include <algorithm>
#include <iostream>
namespace apollo_demo {
// Utility functions implementation
void initializeRandomData(double* data, int size, double min_val, double max_val) {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<double> dist(min_val, max_val);
for (int i = 0; i < size; ++i) {
data[i] = dist(gen);
}
}
void initializeRandomIndices(int* indices, int size, int max_index) {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<int> dist(0, max_index - 1);
for (int i = 0; i < size; ++i) {
indices[i] = dist(gen);
}
}
double computeChecksum(const double* data, int size) {
double sum = 0.0;
for (int i = 0; i < size; ++i) {
sum += data[i];
}
return sum;
}
// VectorAddKernel implementation
void VectorAddKernel::initialize(const ProblemConfig& config) {
size = config.size;
// Allocate memory
a = new double[size];
b = new double[size];
c = new double[size];
// Initialize with random data
initializeRandomData(a, size, 0.0, 1.0);
initializeRandomData(b, size, 0.0, 1.0);
std::memset(c, 0, size * sizeof(double));
}
void VectorAddKernel::cleanup() {
delete[] a;
delete[] b;
delete[] c;
a = b = c = nullptr;
size = 0;
}
KernelFeatures VectorAddKernel::extractFeatures(const ProblemConfig& config) const {
KernelFeatures features;
features.problem_size_log = std::log10(static_cast<float>(config.size));
features.memory_footprint = (3.0f * config.size * sizeof(double)) / (1024.0f * 1024.0f); // MB
features.arithmetic_intensity = 1.0f / (3.0f * sizeof(double)); // 1 op per 3 memory accesses
features.sparsity_level = 0.0f; // Dense operation
features.access_pattern = 0.0f; // Sequential access
return features;
}
// DaxpyKernel implementation
void DaxpyKernel::initialize(const ProblemConfig& config) {
size = config.size;
// Allocate memory
x = new double[size];
y = new double[size];
// Initialize with random data
initializeRandomData(x, size, 0.0, 1.0);
initializeRandomData(y, size, 0.0, 1.0);
alpha = 2.5;
}
void DaxpyKernel::cleanup() {
delete[] x;
delete[] y;
x = y = nullptr;
size = 0;
}
KernelFeatures DaxpyKernel::extractFeatures(const ProblemConfig& config) const {
KernelFeatures features;
features.problem_size_log = std::log10(static_cast<float>(config.size));
features.memory_footprint = (2.0f * config.size * sizeof(double)) / (1024.0f * 1024.0f);
features.arithmetic_intensity = 2.0f / (3.0f * sizeof(double)); // 2 ops per 3 memory accesses
features.sparsity_level = 0.0f;
features.access_pattern = 0.0f;
return features;
}
// MatVecKernel implementation
void MatVecKernel::initialize(const ProblemConfig& config) {
// Make it a square matrix for simplicity
rows = static_cast<int>(std::sqrt(config.size));
cols = rows;
// Allocate memory
A = new double[rows * cols];
x = new double[cols];
y = new double[rows];
// Initialize with random data
initializeRandomData(A, rows * cols, 0.0, 1.0);
initializeRandomData(x, cols, 0.0, 1.0);
std::memset(y, 0, rows * sizeof(double));
}
void MatVecKernel::cleanup() {
delete[] A;
delete[] x;
delete[] y;
A = x = y = nullptr;
rows = cols = 0;
}
KernelFeatures MatVecKernel::extractFeatures(const ProblemConfig& config) const {
KernelFeatures features;
int matrix_size = static_cast<int>(std::sqrt(config.size));
features.problem_size_log = std::log10(static_cast<float>(matrix_size * matrix_size));
features.memory_footprint = ((matrix_size * matrix_size + 2 * matrix_size) * sizeof(double)) / (1024.0f * 1024.0f);
features.arithmetic_intensity = 2.0f / sizeof(double); // 2 ops per memory access
features.sparsity_level = 0.0f;
features.access_pattern = 0.2f; // Some non-sequential due to matrix access
return features;
}
// Stencil1DKernel implementation
void Stencil1DKernel::initialize(const ProblemConfig& config) {
size = config.size;
stencil_radius = std::min(config.stencil_size / 2, 4); // Cap at 4 for safety
// Allocate memory
input = new double[size];
output = new double[size];
weights = new double[2 * stencil_radius + 1];
// Initialize with random data
initializeRandomData(input, size, 0.0, 1.0);
std::memset(output, 0, size * sizeof(double));
// Initialize stencil weights (normalized)
double total_weight = 0.0;
for (int i = 0; i < 2 * stencil_radius + 1; ++i) {
weights[i] = 1.0 / (std::abs(i - stencil_radius) + 1.0);
total_weight += weights[i];
}
for (int i = 0; i < 2 * stencil_radius + 1; ++i) {
weights[i] /= total_weight;
}
}
void Stencil1DKernel::cleanup() {
delete[] input;
delete[] output;
delete[] weights;
input = output = weights = nullptr;
size = 0;
stencil_radius = 0;
}
KernelFeatures Stencil1DKernel::extractFeatures(const ProblemConfig& config) const {
KernelFeatures features;
features.problem_size_log = std::log10(static_cast<float>(config.size));
features.memory_footprint = (2.0f * config.size * sizeof(double)) / (1024.0f * 1024.0f);
int stencil_size = 2 * std::min(config.stencil_size / 2, 4) + 1;
features.arithmetic_intensity = static_cast<float>(stencil_size) / sizeof(double);
features.sparsity_level = 0.0f;
features.access_pattern = 0.1f; // Mostly sequential with some locality
return features;
}
// ReductionKernel implementation
void ReductionKernel::initialize(const ProblemConfig& config) {
size = config.size;
// Allocate memory
data = new double[size];
// Initialize with random data
initializeRandomData(data, size, 0.0, 1.0);
result = 0.0;
}
void ReductionKernel::cleanup() {
delete[] data;
data = nullptr;
size = 0;
result = 0.0;
}
KernelFeatures ReductionKernel::extractFeatures(const ProblemConfig& config) const {
KernelFeatures features;
features.problem_size_log = std::log10(static_cast<float>(config.size));
features.memory_footprint = (config.size * sizeof(double)) / (1024.0f * 1024.0f);
features.arithmetic_intensity = 1.0f / sizeof(double); // 1 op per memory access
features.sparsity_level = 0.0f;
features.access_pattern = 0.0f; // Pure sequential
return features;
}
// SpMVKernel implementation
void SpMVKernel::initialize(const ProblemConfig& config) {
num_rows = static_cast<int>(std::sqrt(config.size));
int num_cols = num_rows;
// Generate sparse matrix in CSR format
// Number of non-zeros based on sparsity level
double density = 1.0 - config.sparsity;
num_nonzeros = static_cast<int>(num_rows * num_cols * density);
num_nonzeros = std::max(num_rows, num_nonzeros); // At least one per row
// Allocate memory
values = new double[num_nonzeros];
col_indices = new int[num_nonzeros];
row_ptr = new int[num_rows + 1];
x = new double[num_cols];
y = new double[num_rows];
// Initialize sparse matrix
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<double> val_dist(0.0, 1.0);
std::uniform_int_distribution<int> col_dist(0, num_cols - 1);
int nnz_idx = 0;
row_ptr[0] = 0;
for (int row = 0; row < num_rows; ++row) {
int nnz_per_row = num_nonzeros / num_rows;
if (row < num_nonzeros % num_rows) nnz_per_row++;
std::vector<int> cols;
for (int i = 0; i < nnz_per_row && nnz_idx < num_nonzeros; ++i) {
cols.push_back(col_dist(gen));
}
std::sort(cols.begin(), cols.end());
for (int col : cols) {
values[nnz_idx] = val_dist(gen);
col_indices[nnz_idx] = col;
nnz_idx++;
}
row_ptr[row + 1] = nnz_idx;
}
// Initialize vectors
initializeRandomData(x, num_cols, 0.0, 1.0);
std::memset(y, 0, num_rows * sizeof(double));
}
void SpMVKernel::cleanup() {
delete[] values;
delete[] col_indices;
delete[] row_ptr;
delete[] x;
delete[] y;
values = nullptr;
col_indices = row_ptr = nullptr;
x = y = nullptr;
num_rows = num_nonzeros = 0;
}
KernelFeatures SpMVKernel::extractFeatures(const ProblemConfig& config) const {
KernelFeatures features;
features.problem_size_log = std::log10(static_cast<float>(config.size));
float density = 1.0f - config.sparsity;
features.memory_footprint = ((config.size * density + config.size) * sizeof(double)) / (1024.0f * 1024.0f);
features.arithmetic_intensity = 2.0f / (sizeof(double) + sizeof(int)); // 2 ops per value+index access
features.sparsity_level = config.sparsity;
features.access_pattern = 0.5f + 0.5f * config.sparsity; // More random with higher sparsity
return features;
}
// IndirectKernel implementation
void IndirectKernel::initialize(const ProblemConfig& config) {
size = config.size;
// Allocate memory
src = new double[size];
dst = new double[size];
indices = new int[size];
// Initialize data
initializeRandomData(src, size, 0.0, 1.0);
std::memset(dst, 0, size * sizeof(double));
// Initialize indices
if (config.use_indirect) {
// Random access pattern
initializeRandomIndices(indices, size, size);
} else {
// Sequential access pattern
for (int i = 0; i < size; ++i) {
indices[i] = i;
}
}
}
void IndirectKernel::cleanup() {
delete[] src;
delete[] dst;
delete[] indices;
src = dst = nullptr;
indices = nullptr;
size = 0;
}
KernelFeatures IndirectKernel::extractFeatures(const ProblemConfig& config) const {
KernelFeatures features;
features.problem_size_log = std::log10(static_cast<float>(config.size));
features.memory_footprint = (2.0f * config.size * sizeof(double) + config.size * sizeof(int)) / (1024.0f * 1024.0f);
features.arithmetic_intensity = 1.0f / (2.0f * sizeof(double) + sizeof(int));
features.sparsity_level = 0.0f;
features.access_pattern = config.use_indirect ? 1.0f : 0.0f;
return features;
}
// Factory function
std::unique_ptr<KernelBase> createKernel(const std::string& kernel_name) {
if (kernel_name == "VectorAdd") {
return std::make_unique<VectorAddKernel>();
} else if (kernel_name == "DAXPY") {
return std::make_unique<DaxpyKernel>();
} else if (kernel_name == "MatVec") {
return std::make_unique<MatVecKernel>();
} else if (kernel_name == "Stencil1D") {
return std::make_unique<Stencil1DKernel>();
} else if (kernel_name == "Reduction") {
return std::make_unique<ReductionKernel>();
} else if (kernel_name == "SpMV") {
return std::make_unique<SpMVKernel>();
} else if (kernel_name == "Indirect") {
return std::make_unique<IndirectKernel>();
}
return nullptr;
}
} // namespace apollo_demo
Reading through the Apollo documentation, I think this setup could be a lot less verbose if I were to use the Apollo-enabled RAJA fork from (https://github.com/LLNL/RAJA/compare/develop...ggeorgakoudis:RAJA:feature/apollo). But at this point that’s an extremely old version of RAJA, and I don’t really trust Claude to be able to cope with the older API and any important changes that might have happened since.
For the parameters that it chose by default, we don’t really get anything exciting out of Apollo. It determines that for all of those kernels, with an input size of around 10^5 the fastest execution policy is just the serial one and that the OpenMP thread overhead isn’t worth it. But if I increase the problem size by a factor of 100, it starts picking other OpenMP policies. It also really helps if I make sure my system isn’t doing anything else at the time, as the OpenMP policies with explicit batch policies are the ones that suffer the most if other processes are taking resources:
Command: APOLLO_POLICY_MODEL='DecisionTree,explore=RoundRobin,max_depth=4' ./apollo_raja_demo_cpu --adaptive
Apollo-RAJA CPU Demonstration
==============================
Configuration:
Number of policies: 5
Available policies:
0: Sequential
1: OpenMP Default
2: OpenMP Static-16
3: OpenMP Dynamic-8
4: OpenMP Guided
OpenMP threads: 8
Apollo Policy Model: DecisionTree,explore=RoundRobin,max_depth=4
== APOLLO: Looked for APOLLO_COLLECTIVE_TRAINING with getenv(), found nothing, using '0' (default) instead.
== APOLLO: Looked for APOLLO_LOCAL_TRAINING with getenv(), found nothing, using '1' (default) instead.
== APOLLO: Looked for APOLLO_SINGLE_MODEL with getenv(), found nothing, using '0' (default) instead.
== APOLLO: Looked for APOLLO_REGION_MODEL with getenv(), found nothing, using '1' (default) instead.
== APOLLO: Looked for APOLLO_GLOBAL_TRAIN_PERIOD with getenv(), found nothing, using '0' (default) instead.
== APOLLO: Looked for APOLLO_PER_REGION_TRAIN_PERIOD with getenv(), found nothing, using '0' (default) instead.
== APOLLO: Looked for APOLLO_TRACE_POLICY with getenv(), found nothing, using '0' (default) instead.
== APOLLO: Looked for APOLLO_STORE_MODELS with getenv(), found nothing, using '0' (default) instead.
== APOLLO: Looked for APOLLO_TRACE_RETRAIN with getenv(), found nothing, using '0' (default) instead.
== APOLLO: Looked for APOLLO_TRACE_ALLGATHER with getenv(), found nothing, using '0' (default) instead.
== APOLLO: Looked for APOLLO_TRACE_BEST_POLICIES with getenv(), found nothing, using '0' (default) instead.
== APOLLO: Looked for APOLLO_RETRAIN_ENABLE with getenv(), found nothing, using '0' (default) instead.
== APOLLO: Looked for APOLLO_RETRAIN_TIME_THRESHOLD with getenv(), found nothing, using '2.0' (default) instead.
== APOLLO: Looked for APOLLO_RETRAIN_REGION_THRESHOLD with getenv(), found nothing, using '0.5' (default) instead.
== APOLLO: Looked for APOLLO_TRACE_CSV with getenv(), found nothing, using '0' (default) instead.
== APOLLO: Looked for APOLLO_PERSISTENT_DATASETS with getenv(), found nothing, using '0' (default) instead.
== APOLLO: Looked for APOLLO_STORE_EXEC_INFO with getenv(), found nothing, using '0' (default) instead.
== APOLLO: Looked for APOLLO_OUTPUT_DIR with getenv(), found nothing, using '.apollo' (default) instead.
== APOLLO: Looked for APOLLO_DATASETS_DIR with getenv(), found nothing, using 'datasets' (default) instead.
== APOLLO: Looked for APOLLO_TRACES_DIR with getenv(), found nothing, using 'traces' (default) instead.
== APOLLO: Looked for APOLLO_MODELS_DIR with getenv(), found nothing, using 'models' (default) instead.
============================================================
ADAPTIVE SCENARIO: Apollo learns optimal policies
============================================================
--- EXPLORATION PHASE ---
Apollo explores different policies...
=== Running VectorAdd Kernel ===
Problem size: 100000
Iterations: 5
Apollo selected: Sequential (policy 0)
Iteration 1: 0.032 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 2: 0.182 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 3: 0.173 ms
Apollo selected: OpenMP Dynamic-8 (policy 3)
Iteration 4: 0.799 ms
Apollo selected: OpenMP Guided (policy 4)
Iteration 5: 0.092 ms
Statistics:
Average: 0.256 ms
Min: 0.032 ms
Max: 0.799 ms
=== Running DAXPY Kernel ===
Problem size: 100000
Iterations: 5
Apollo selected: Sequential (policy 0)
Iteration 1: 0.025 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 2: 0.054 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 3: 0.086 ms
Apollo selected: OpenMP Dynamic-8 (policy 3)
Iteration 4: 0.126 ms
Apollo selected: OpenMP Guided (policy 4)
Iteration 5: 0.124 ms
Statistics:
Average: 0.083 ms
Min: 0.025 ms
Max: 0.126 ms
=== Running Stencil1D Kernel ===
Problem size: 100000
Iterations: 5
Apollo selected: Sequential (policy 0)
Iteration 1: 0.132 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 2: 0.131 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 3: 0.145 ms
Apollo selected: OpenMP Dynamic-8 (policy 3)
Iteration 4: 0.172 ms
Apollo selected: OpenMP Guided (policy 4)
Iteration 5: 0.140 ms
Statistics:
Average: 0.144 ms
Min: 0.131 ms
Max: 0.172 ms
=== Running Reduction Kernel ===
Problem size: 100000
Iterations: 5
Apollo selected: Sequential (policy 0)
Iteration 1: 0.100 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 2: 0.086 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 3: 0.077 ms
Apollo selected: OpenMP Dynamic-8 (policy 3)
Iteration 4: 0.129 ms
Apollo selected: OpenMP Guided (policy 4)
Iteration 5: 0.102 ms
Statistics:
Average: 0.099 ms
Min: 0.077 ms
Max: 0.129 ms
=== Running VectorAdd Kernel ===
Problem size: 1000000
Iterations: 5
Apollo selected: Sequential (policy 0)
Iteration 1: 1.090 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 2: 0.569 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 3: 1.090 ms
Apollo selected: OpenMP Dynamic-8 (policy 3)
Iteration 4: 0.679 ms
Apollo selected: OpenMP Guided (policy 4)
Iteration 5: 0.522 ms
Statistics:
Average: 0.790 ms
Min: 0.522 ms
Max: 1.090 ms
=== Running DAXPY Kernel ===
Problem size: 1000000
Iterations: 5
Apollo selected: Sequential (policy 0)
Iteration 1: 1.183 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 2: 0.459 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 3: 0.733 ms
Apollo selected: OpenMP Dynamic-8 (policy 3)
Iteration 4: 0.709 ms
Apollo selected: OpenMP Guided (policy 4)
Iteration 5: 0.369 ms
Statistics:
Average: 0.691 ms
Min: 0.369 ms
Max: 1.183 ms
=== Running Stencil1D Kernel ===
Problem size: 1000000
Iterations: 5
Apollo selected: Sequential (policy 0)
Iteration 1: 1.275 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 2: 0.764 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 3: 0.950 ms
Apollo selected: OpenMP Dynamic-8 (policy 3)
Iteration 4: 0.965 ms
Apollo selected: OpenMP Guided (policy 4)
Iteration 5: 0.618 ms
Statistics:
Average: 0.914 ms
Min: 0.618 ms
Max: 1.275 ms
=== Running Reduction Kernel ===
Problem size: 1000000
Iterations: 5
Apollo selected: Sequential (policy 0)
Iteration 1: 0.983 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 2: 0.416 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 3: 0.385 ms
Apollo selected: OpenMP Dynamic-8 (policy 3)
Iteration 4: 0.616 ms
Apollo selected: OpenMP Guided (policy 4)
Iteration 5: 0.305 ms
Statistics:
Average: 0.541 ms
Min: 0.305 ms
Max: 0.983 ms
--- TRAINING PHASE ---
Apollo has trained models based on exploration data
--- EXPLOITATION PHASE ---
Apollo uses learned models to select optimal policies...
=== Running VectorAdd Kernel ===
Problem size: 10000000
Iterations: 5
Apollo selected: Sequential (policy 0)
Iteration 1: 18.672 ms
Apollo selected: Sequential (policy 0)
Iteration 2: 5.530 ms
Apollo selected: Sequential (policy 0)
Iteration 3: 5.048 ms
Apollo selected: Sequential (policy 0)
Iteration 4: 5.151 ms
Apollo selected: Sequential (policy 0)
Iteration 5: 5.259 ms
Statistics:
Average: 7.932 ms
Min: 5.048 ms
Max: 18.672 ms
=== Running DAXPY Kernel ===
Problem size: 10000000
Iterations: 5
Apollo selected: Sequential (policy 0)
Iteration 1: 4.582 ms
Apollo selected: Sequential (policy 0)
Iteration 2: 4.827 ms
Apollo selected: Sequential (policy 0)
Iteration 3: 4.528 ms
Apollo selected: Sequential (policy 0)
Iteration 4: 4.759 ms
Apollo selected: Sequential (policy 0)
Iteration 5: 4.752 ms
Statistics:
Average: 4.690 ms
Min: 4.528 ms
Max: 4.827 ms
=== Running Stencil1D Kernel ===
Problem size: 10000000
Iterations: 5
Apollo selected: OpenMP Default (policy 1)
Iteration 1: 5.894 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 2: 6.527 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 3: 6.348 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 4: 6.901 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 5: 6.106 ms
Statistics:
Average: 6.355 ms
Min: 5.894 ms
Max: 6.901 ms
=== Running Reduction Kernel ===
Problem size: 10000000
Iterations: 5
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 1: 3.036 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 2: 2.883 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 3: 3.074 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 4: 2.620 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 5: 2.647 ms
Statistics:
Average: 2.852 ms
Min: 2.620 ms
Max: 3.074 ms
=== Running VectorAdd Kernel ===
Problem size: 100000000
Iterations: 5
Apollo selected: Sequential (policy 0)
Iteration 1: 526.750 ms
Apollo selected: Sequential (policy 0)
Iteration 2: 84.982 ms
Apollo selected: Sequential (policy 0)
Iteration 3: 48.321 ms
Apollo selected: Sequential (policy 0)
Iteration 4: 59.781 ms
Apollo selected: Sequential (policy 0)
Iteration 5: 751.197 ms
Statistics:
Average: 294.206 ms
Min: 48.321 ms
Max: 751.197 ms
=== Running DAXPY Kernel ===
Problem size: 100000000
Iterations: 5
Apollo selected: Sequential (policy 0)
Iteration 1: 81.666 ms
Apollo selected: Sequential (policy 0)
Iteration 2: 72.213 ms
Apollo selected: Sequential (policy 0)
Iteration 3: 46.080 ms
Apollo selected: Sequential (policy 0)
Iteration 4: 43.956 ms
Apollo selected: Sequential (policy 0)
Iteration 5: 44.062 ms
Statistics:
Average: 57.595 ms
Min: 43.956 ms
Max: 81.666 ms
=== Running Stencil1D Kernel ===
Problem size: 100000000
Iterations: 5
Apollo selected: OpenMP Default (policy 1)
Iteration 1: 63.077 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 2: 52.470 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 3: 52.742 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 4: 52.084 ms
Apollo selected: OpenMP Default (policy 1)
Iteration 5: 53.496 ms
Statistics:
Average: 54.774 ms
Min: 52.084 ms
Max: 63.077 ms
=== Running Reduction Kernel ===
Problem size: 100000000
Iterations: 5
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 1: 41.429 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 2: 25.145 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 3: 25.065 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 4: 24.666 ms
Apollo selected: OpenMP Static-16 (policy 2)
Iteration 5: 25.017 ms
Statistics:
Average: 28.264 ms
Min: 24.666 ms
Max: 41.429 msSo overall pretty interesting! In the state the project is currently in, it is not at all obvious to me how I would use it in a codebase that isn’t already structured around RAJA execution policies.